AI success depends on clean, high-quality data; messy or inconsistent inputs lead to unreliable outputs.
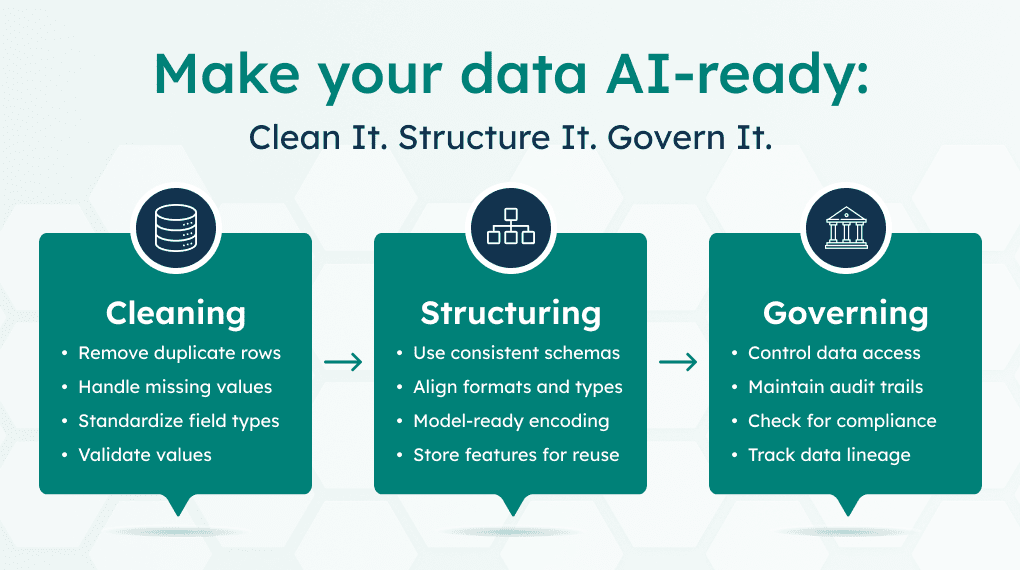
Data preparation starts with cleaning, removing duplicates, fixing missing values, and keeping formats consistent.
Structuring turns raw data into usable features, enabling models to recognize patterns and generate accurate insights.
Governance keeps data usable over time through ownership, access controls, versioning, and documentation.
Businesses that invest in readiness early avoid costly fixes later, ensuring AI models are accurate, scalable, and easier to maintain.
Article Contents
A survey by Bain & Company reveals that 95% of companies in the United States utilize Generative AI in some capacity. Although the adoption of this technology is increasing, it is hindered by the quality of the outputs. One of the main reasons for this issue is the lack of high-quality data.
So, before your business can realize those advantages, your data has to be ready for consumption by the AI.
In a study by Ernst & Young, 83% of senior business leaders said AI adoption would be faster with a stronger data infrastructure in place.
Strengthening your data infrastructure hinges on providing quality data that’s properly prepared for the AI to consume. The quality of your AI solution directly relates to the quality of your data.
Data readiness involves several factors:
Accessibility and organization
Ownership and governance
Data domains
Data definition, glossary, and cataloging
Optimization and correction
Bias
This article breaks down what each step involves and how they work together to achieve the intended results.
Data Preparation Is Key
Understanding and preparing your data for the task you want to automate with AI is essential, as it is critical for a successful deployment. You can’t just throw disparate datasets into a model and expect magic. AI is not a miracle worker; it’s a pattern recognizer. For it to deliver value, your team must understand:
Where does the data come from
How it’s formatted
Whether a structure exists across data sources
What gaps or inconsistencies might exist
Let’s take an e-commerce company working on a product recommendation engine. The goal is to help users discover products they will likely buy based on their browsing and purchase history.
Now, in doing this, a few situations might arise. They’re pulling data from multiple sources, including website analytics, purchase records, customer profiles, and the product catalog. Some of these datasets might use different formats, and a few might have missing fields or duplicate entries.
For example, a customer might be listed twice under two slightly different email addresses. Product information might be outdated or missing categories. Web logs could be unstructured and hard to analyze without cleaning. Some datasets might not even have clear rules around who should be able to access or update them.
When things like this pile up, building a working model becomes difficult. The output is only as reliable as the input, and if the data isn’t prepared correctly, the model won’t know what to learn from or how to respond. Before your team builds anything, they need to get the data ready. And that starts with cleaning.
Cleaning Comes First
Before the data goes anywhere, it needs a cleanup to fix what would otherwise trip things up.
One of the easiest ways is to start with duplicates. If the same entry appears twice, the model might weigh it twice, which throws everything off.
Then you look for missing values. If a price is blank or a session ID is gone, you either fill it in or remove the row. But you decide that with a plan, not at random.
After that, it’s about keeping formats consistent. If one table shows dates as DD/MM/YYYY and another uses MM-DD-YY, they won’t work well together.
Cleaning also includes catching anything that just doesn’t make sense. Maybe someone entered “100000” for quantity instead of “10.” These things seem small, but they get amplified when AI models start learning from them.
The point of cleaning is to make the data stable enough to use. You still want the quirks that matter, like edge cases or outliers that help the model learn. Once the cleanup is done, the next step is to give the data a proper shape.
Structuring Makes It Work
Once the data is clean, it needs a structure that the model can use. This process gives you a better grasp of how your data is organized and provides your AI with patterns it can recognize to generate accurate insights.
For example, you might break a full name into first and last names. Or convert free-text product reviews into categories like positive, neutral, or negative.
This is also where unstructured logs or user actions become more useful. Instead of just storing that a customer “clicked on a product,” you translate that into behavior patterns like “viewed similar items” or “added to cart but didn’t buy.”
You might also need to join multiple sources together. Maybe your product database doesn’t match the analytics logs one-to-one. That’s fine, but you’ll need a way to connect the dots. Without that step, your model ends up guessing with partial context.
Structuring is what makes the cleaned data usable. It gives your model features to work with things it can learn from.
This is also the point where rules and documentation start to matter. If two teams pull the same data and shape it differently, their results won’t match.
Once the raw data is cleaned, it must be organized into usable, model-friendly formats. That includes transforming it into features that the input AI models rely on to make predictions. These features could be anything from how recently a customer visited the site to how often they reorder the same product.
Many teams use a feature store to avoid duplication and inconsistency. It’s a shared space where curated, reusable features are stored and updated, which keeps things consistent across different teams and models and speeds up development because no one has to rebuild the same logic from scratch.
Now that the data is shaped into features, one last step before modeling is governance.
Governance Keeps It Clean Over Time
Once the data is structured, you need to ensure it stays usable as systems grow and change.
Governance defines how data should be handled, who can access it, how changes are tracked, and what the standards are across teams.
A few things make up solid governance:
Defined access controls to limit exposure of sensitive fields
Versioning that tracks changes and avoids overwriting valuable data
Assigned ownership so datasets have clear accountability
Documentation that removes guesswork for anyone using or updating the data
How to Make Raw Data Work for AI Models
Even after cleaning and structuring your data, you are almost there! For Generative AI systems, you can probably use the dataset as is with your tasks; for bespoke AI systems, you might need to do a tiny bit more processing to extract relevant features to train the model on.
It sounds technical, but the idea is simple. You look at your data and ask: what parts of this are useful? Then you translate those parts into clear signals a model can learn from.
For example:
A timestamp alone doesn’t mean much. But you start to see behavior patterns if you pull out the hour, day of the week, or time since the last action.
A list of product names can’t be fed directly into a model. But if you group them into categories or tag them as high/low value, that’s something the model can use.
Click logs, purchase history, and user activity must often be condensed into summaries like average time on site or number of purchases last month.
Getting this part right often needs help from people who understand both the business and the data. They know what behavior matters and how to shape it into useful signals.
If done well, this step boosts model accuracy and reduces noise. It also makes the model easier to maintain and scale because your inputs are stable and reliable.
Once these signals are ready, the next step is to manage and deliver them in a way that works for the whole team.
Start with the Right Foundation
If your data is messy, your AI won’t perform well. It’s that simple. Cleaning, structuring, and governing data makes models useful and accurate.
Many teams overlook this early stage and end up fixing problems after deployment. A better way is to assess readiness now, before investing time and resources.
Taazaa’s AI Readiness Assessment helps you evaluate your organization’s strengths and gaps across data, technology, processes, and people in less than five minutes. You’ll receive a free report highlighting where you’re ready and what you need to improve.
FAQs
Q3. How to make content AI-ready?
Content becomes AI-ready when it’s structured and labeled in ways machines can process. That means clear formats, consistent metadata, and avoiding ambiguity. For example, tagging articles with topics, authors, and categories makes them easier for AI systems to analyze, recommend, or repurpose.
Q2. What is data readiness for AI?
Data readiness means your information is accessible, consistent, and trustworthy enough for AI to use. It’s not about having more data, but about having usable data that’s well-governed, clearly defined, and aligned with business goals. Without it, even advanced AI models will struggle.
Q1. How do you prepare your data for AI?
Start by cleaning it, removing duplicates, fixing missing values, and keeping formats consistent. Then, structure it into usable features that models can learn from, like turning raw logs into behavior patterns. Finally, establish governance so the data stays accurate and reliable as systems grow.













.svg)






